Introduction
Artificial intelligence is certainly one of the most discussed topics today. New developments are announced almost every day, and companies have been adopting a wide range of solutions at a fast pace, hoping to gain productivity and see financial returns as quickly as possible.
In a short time, technical terms such as machine learning, transformer, prompt, token, autonomous agents, and MCP started appearing in meetings, news articles, software products, and workplace conversations. For people who do not work directly in a technology-related field, understanding all these complex terms can be challenging, especially given the lack of familiarity with the area and the speed at which new developments are announced.
This article covers the main concepts in the field of artificial intelligence, or simply AI, focusing on the terms most commonly used today. The goal is to provide clear definitions, practical examples, and simple comparisons so readers can understand how these ideas connect in real-world use.
What Is Artificial Intelligence?
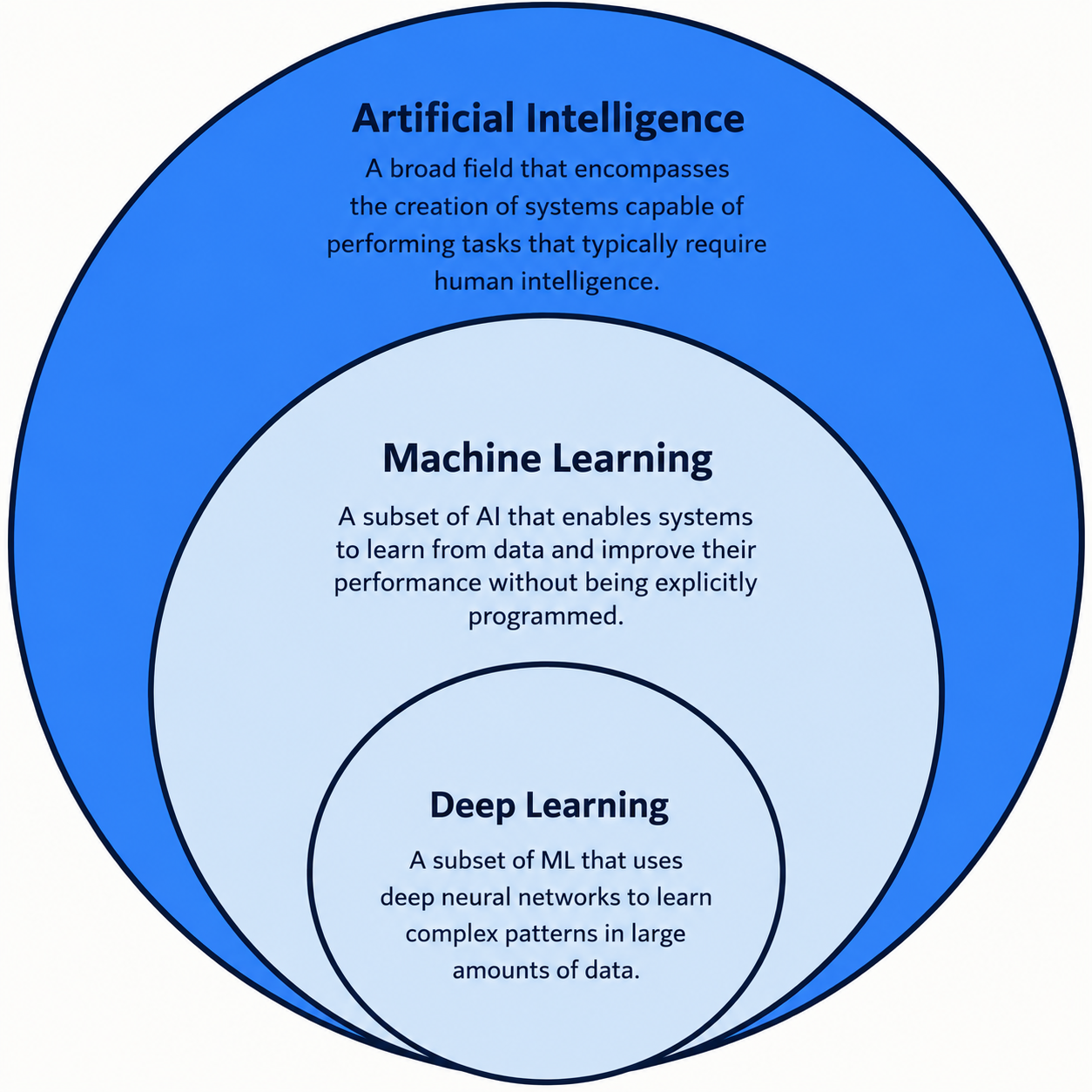
Artificial intelligence is the broadest field of study in this area. There are many definitions of what the field means exactly, but in simple terms, it brings together techniques that allow computer systems to perform tasks related to perception, prediction, classification, language, decision-making, and automation.
Within this field, there are different areas of study and application. We will highlight two of them, considering the current context of AI adoption in the market.
The first is machine learning.
Machine learning is a way of building systems that learn patterns from data, instead of relying only on rules manually written by programmers.
Let’s use an analogy with a person learning to shoot a basketball with the help of a coach. At first, this person misses almost every shot. The ball hits the rim, goes too hard, or falls short. But the coach does something important: after each attempt, he gives feedback to help improve the shot:
- "You released the ball too quickly."
- "Bend your knees more."
- "Aim a little higher."
Over time, the athlete starts to identify patterns:
- When he uses a certain amount of force, he makes the shot more often.
- When he positions his arm correctly, the shot improves.
- When he repeats the wrong movements, the result gets worse.
After many attempts, his brain learns which movements increase the chances of success.
Machine learning works in a similar way. Instead of receiving a rigid list of instructions for every possible situation, the system observes data, adjusts its internal parameters, and learns to recognize regularities. This is what enables things like email spam filters, movie recommendations on streaming platforms, fraud detection, and speech recognition.
The second area is deep learning.
This is a subfield of machine learning. It uses neural networks with multiple layers to learn progressively more complex representations of data. These networks were broadly inspired by how neurons work, but they are mathematical and computational structures, not literal copies of the human brain.
Now imagine a professional soccer player who needs to make complex decisions during a match.
A beginner usually learns more direct instructions:
- "Pass to the open player."
- "Shoot when you are close to the goal."
- "Mark the nearest opponent."
This type of learning resembles a simpler pattern-recognition logic.
An elite professional player, however, does much more than follow direct instructions. Over many years, he learns subtle patterns of the game:
- He recognizes tactical formations in a few seconds.
- He predicts opponents’ future movements.
- He interprets body language.
- He notices open spaces on the field.
- He adjusts decisions based on pressure, time, and match context.
What is most interesting is that he does not depend on a single simple rule to do this. The brain organizes multiple layers of understanding.
First, he notices basic signals:
- The ball is coming in a certain direction.
- An opposing player has started running.
- A teammate is moving down the sideline.
Then he combines these signals into broader interpretations:
- The opposing team is trying to close down the midfield.
- An open space is appearing behind the defense.
- The goalkeeper is too far off his line.
Next, he combines those interpretations again into a more complex decision:
- If he passes the ball into that space now, his teammate may get there before the defender and create a clear scoring opportunity.
Deep learning works in a similar way in terms of progressively building representations. In an image recognition system, for example, the first layers may identify lines, edges, and contrasts. Intermediate layers may combine these signals into shapes, textures, and parts of objects. Deeper layers may recognize more complete concepts, such as faces, animals, signs, vehicles, or elements in a scene.
This example helps explain why deep learning has become so important in areas such as computer vision, speech recognition, machine translation, and language models. It is especially useful when data is rich, varied, and difficult to describe using only manual rules.
There are other areas of study and AI techniques used for different purposes. The goal of this article is to help readers understand that not every AI system depends on the same technique, and that the most common terms in the market represent different parts of this ecosystem.
What Is an AI Model?
After understanding machine learning, it becomes easier to understand what an AI model is. In practical terms, a model is the system trained from data to recognize patterns and produce some useful output. That output may be a classification, a prediction, a recommendation, a summary, an image, a piece of code, or a response in natural language.
A simple way to visualize this is to think of the model as a trained professional that transforms inputs into likely responses. It receives a request, analyzes the available signals, and produces an output based on what it learned during training.
Returning to the sports analogy, imagine two athletes who play the same sport. Both play soccer, but they were trained in different ways. One trained mainly on finishing. The other trained on passing, reading the game, and positioning. Faced with the same play, each may make different decisions because their training, experience, and internal patterns are different.
Something similar happens with AI models. Two models may receive the same request and respond in different ways because they were trained with different data, goals, architectures, and adjustments.
In the case of language models, this idea becomes even more concrete. ChatGPT is an OpenAI interface that can use different models. Gemini is a family of models from Google, with versions designed for different types of tasks. Claude, from Anthropic, is also a family of models used for conversation, writing, analysis, programming, and other activities.
In all these cases, the user usually interacts with a product or assistant. Behind the screen, there are one or more models processing the request and generating the response.
This helps separate two things that are often mixed together. ChatGPT, Gemini, and Claude can be seen as products, interfaces, and user experiences. GPT, Gemini, and Claude may also appear as names of model families behind those experiences, depending on the context in which the terms are used.
This is also where the differences between faster models and models with more reasoning effort come in. In many current products, users may end up interacting with a model optimized for quick responses, which is ideal for simple tasks, or with a model configured to use more internal steps before responding, which may improve performance on more complex problems.
The best way to understand this difference is to imagine two experienced professionals. One answers a direct question immediately. The other pauses, organizes hypotheses, evaluates risks, mentally reviews the problem, and only then responds. In AI models, this difference becomes a trade-off between speed, computational cost, and depth of processing.
One important note is worth making. When we say that a model learns patterns, we are talking about a statistical and computational process. It does not understand the world the way a person does, and it does not store facts the way an encyclopedia does. It calculates likely responses based on training, available context, and received instructions. This matters because modern artificial intelligence systems do not have consciousness in the same way human beings do, at least not for now.
Transformer Architecture
Many of the most well-known language models today were built based on the Transformer architecture, introduced in 2017 in the paper Attention Is All You Need.
The most important word here is attention. In a Transformer, the system can evaluate which parts of a text sequence are more relevant in relation to others. Instead of processing a sentence only as a rigid sequence of words one after another, the model can relate different parts of the context at the same time.
Think of someone reading a long contract. To understand a clause near the end of a document, perhaps a mortgage contract or a vehicle purchase agreement, that person may need to remember a definition from the beginning, an exception in the middle, and a condition written in another section. A good reader does not interpret each line in isolation. He connects information spread across the text.
The attention mechanism works in a similar way. It helps the model identify which sections deserve more weight at that moment. If a previous word, phrase, or instruction is important for interpreting what comes next, the model can use that relationship during processing.
This architecture was decisive for the advancement of Large Language Models, or LLMs, which represent the main AI models of the moment, such as GPT 5.5, Claude Opus and Claude Sonnet, Gemini, Deepseek v4, among others. Since text is converted into tokens and processed within a context window, the Transformer helps the model better handle textual coherence, long-range relationships, and dependencies between distant sections.
At the same time, it is important to treat the Transformer as an architecture, not as a synonym for artificial intelligence as a whole. It is extremely influential in the current generation of language models, but the AI field continues to research other architectures, methods, and combinations of techniques.
For an introductory article, it is enough to understand that Transformer is one of the technical foundations that made modern language models much more useful for tasks that depend on context.
What Is Generative AI?
We finally arrive at the concept of Generative Artificial Intelligence. This is the part of AI focused on creating new content. This content may include text, images, audio, video, code, and other formats. The central point is that the system produces a new output based on patterns learned during training and on the context of the request it receives. This ability depends in part on generalization, which is the model’s capacity to apply learned patterns to new situations.
Generative models learn patterns of form, content, and structure from large datasets. Then they use those patterns to compose new outputs according to the user’s request.
This distinction matters because many people imagine generative AI as a kind of disguised search engine. In some systems, AI can be combined with internet search, databases, internal documents, or external tools. Even so, the central logic of the generative model is to produce an output from the received context and the learned patterns.
That is why generative tools can write an email, create an image from a description, summarize a report, suggest code, or adapt a text for a different audience. The same general principle applies to different types of content, although each modality requires its own techniques, data, and adjustments.
Think about how a restaurant kitchen works. A cook may have studied hundreds of recipes and techniques. When an order comes in, he combines ingredients, methods, and experience to prepare a new dish. The result depends on his repertoire, the instructions received, and the available ingredients. With generative AI, the user’s request works as part of that direction.
What Is a Multimodal Model?
If generative AI describes the type of task, multimodality describes the type of data. A multimodal model is one that can handle more than one mode of information, such as text, images, audio, video, and code.
An intuitive way to think about this is to imagine a doctor working on a patient’s diagnosis. He may read the patient’s history, look at imaging exams, listen to the description of symptoms, compare lab results, and bring all of that together into a more complete analysis. The richness of the evaluation comes precisely from combining different types of information.
A multimodal system follows a similar logic in computational processing. It may receive, for example, an image and a question in text. It can analyze a chart, interpret a screenshot, summarize audio, or combine visual and textual information to produce a response.
This helps explain a common confusion. Generative AI and multimodal AI are different concepts. One system may generate only text. Another may receive text and images. Another may receive audio, images, and text, and generate a textual response. In some cases, these capabilities overlap, but the concepts describe different aspects.
In practice, multimodality matters because it brings AI closer to the way we deal with information in everyday life. People read, see, listen, compare, and combine signals all the time. Multimodal models try to bring this combination into computational processing.
This creates room for more natural applications. A user can send a photo of a faulty device and ask for guidance. A professional can send a chart and ask for an analysis. A student can show an image of an exercise and ask for an explanation. Instead of depending only on typed text, the system can work with more forms of input.
What Are Tokens?
To understand how language models work, it is necessary to understand token. A token is the basic unit of text processed by the model. Many people imagine that a token is the same as a word, but that is only an approximation. A token can be a full word, part of a word, a space, a punctuation mark, or a short combination of characters, depending on the tokenization system.
A practical way to think about this is to imagine that, before working with a sentence, the model breaks it down into small manageable pieces. These pieces are the tokens. After that, the system processes relationships between them to interpret the context and generate the next output.
Imagine a child building a sentence with blocks. Some blocks represent full words. Others represent parts of words. Others represent punctuation. To form a response, the child needs to organize those blocks in sequence. Language models work with a computational version of this idea.
This concept becomes more concrete with an approximate calculation often used in the market. In English, 1 token usually corresponds to about 4 characters, or roughly three quarters of a word. Note that this is only an average, not a fixed rule valid for all models that work with tokens. In Portuguese, the proportion may vary because words have a different structure and use accents. Even so, this reference helps understand the general order of magnitude.
A text with 400 characters, for example, may have around 100 tokens, depending on the language, spaces, punctuation, and model used.
This matters for several reasons. First, it limits the total amount of information a model can process at once. Instead of thinking only in number of pages, AI systems work with context windows measured in tokens. Second, because cost and performance are also often calculated based on tokens. Third, the way text is written affects the volume of information sent to the model.
When someone sends a long message to an AI system, the model does not receive it as a single indivisible block. It turns the content into tokens and operates on those units. This is a technical detail, but it has a major practical effect.
What Are Input Tokens and Output Tokens?
In addition to the general concept of token, there is an important operational distinction. Input tokens are the tokens sent to the model. This includes the user’s question, additional context, system instructions, and sometimes earlier parts of the conversation. Output tokens are the tokens generated by the model in its response.
In AI systems, context usage and often the cost involved depend on these two dimensions.
If the user sends a prompt, a concept we will cover shortly, that is very large, input consumption increases. If the user asks for a very long response, output consumption also grows. In real applications, this affects budget, speed, and the available context limit.
For example, consider a company that uses AI to analyze contracts. If each request includes the entire contract, attachments, negotiation history, and detailed instructions, the volume of input tokens will be high. If the response needs to include a complete analysis, risks, clause suggestions, and an executive summary, the volume of output tokens will also be high. This can affect output quality, since a large volume of context may make it harder for the model to focus on the most relevant information, as well as the final cost, which will likely be high depending on the AI model used.
What Is Token Caching?
Another concept that often sounds too technical is token caching, also called prompt caching in some contexts. The general idea is simple: when part of the context has already been processed recently and remains the same, the system can reuse that work instead of recalculating everything from scratch.
Imagine someone reviewing a long document throughout the day. If the first chapters remain identical and only the ending changed, that person does not need to reread everything from the beginning with the same level of attention. He can focus on the changed section and reuse the understanding already built around the rest.
Caching works like this temporary reuse of processing. In applications with long or repetitive prompts, it can reduce processing time and cost, depending on the platform, model, and usage conditions.
But there is an important caution: cache should not be confused with permanent memory. It does not mean that the AI has started remembering data in a stable and long-lasting way. It only means that certain sections of context can be reused for some time under specific conditions.
For people who use AI in products, this concept is useful because it explains why some long interactions can become more efficient. For those just getting started, it is enough to understand that token caching is a way to avoid computational rework when parts of the context repeat, and especially to avoid very expensive bills when using AI to process long texts or other content that requires high token consumption.
What Is a Prompt?
Prompt is the instruction, request, and context you provide to the model. In simple terms, it is what guides the AI’s response. It can be a short question, a text with context, a detailed task, a set of rules, or a combination of all these elements.
Basically, when you open ChatGPT, Gemini, Claude, or another similar chat and ask the AI a question, what you are writing is a prompt.
A direct way to understand this is to think of a briefing. When someone asks for work without context, a clear goal, or criteria, the chance of receiving something generic increases. When the request includes context, constraints, desired format, and examples, the chance of receiving something useful grows significantly.
Compare these two requests:
- "Write a text about sales."
- "Write a short email for customers who abandoned their cart in an online clothing store, using a polite tone, offering help, and avoiding aggressive sales language."
The second request provides context, audience, goal, format, and constraints. For that reason, it tends to produce a more useful response.
That is why people talk about prompt engineering. The name may sound sophisticated, but the central logic is simple: formulate the request better to get better results. This involves clarity, structure, examples, goals, and limits. This point is especially important because many people treat prompts like a secret trick. In practice, the value lies in knowing how to explain the task well. In professional environments, this makes a difference in quality, consistency, and the reuse of workflows.
In a company, for example, well-written prompts can standardize analyses, reports, contract reviews, customer support responses, meeting summaries, and documentation generation. The gain comes less from special phrases and more from turning process knowledge into clear instructions.
What Is MCP?
MCP stands for Model Context Protocol. It is an open standard designed to connect AI applications to external systems, such as files, databases, tools, and workflows.
Think about an Excel spreadsheet or Word document you created for a specific purpose at work. Also think about the system your company uses for human resources management, ticket creation, and other activities.
MCP is basically a protocol that allows these different systems and applications to connect with artificial intelligence. The main difference from a traditional system is that in a traditional system, there is usually a predefined task to execute an action, or a person interacting with the system to complete a task. In the context of artificial intelligence, MCP allows an AI agent to make decisions and interact with systems and applications on its own. Basically, the AI decides how to use the system and uses the available commands and instructions as it sees fit.
This concept matters because, as AI moves beyond simple chat and starts interacting with real systems, an organized way of connecting becomes more valuable. MCP helps different applications adopt a common standard for integration with AI systems, which allows new models to be integrated with existing systems without major headaches.
For a nontechnical reader, the central idea is this: MCP helps AI communicate with tools, data, and real-world services in a standardized way.
This concept is especially relevant in the context of autonomous agents, the next concept covered, because agents depend precisely on the ability to access resources outside the text box. An agent that only chats has limited usefulness. An agent that consults tools, interprets data, and performs actions can participate in real workflows.
What Is an Autonomous Agent?
The term autonomous agent has gained a lot of visibility, but it is not always used precisely. In general terms, an agent is an AI system that not only answers questions, but also decides steps, uses tools, and performs actions on behalf of the user within certain limits.
A simple way to visualize this is to compare two types of assistant.
The first assistant only answers questions. You ask what the delivery deadline is for a product, and it responds based on available information.
The second assistant receives a goal. It checks the order, verifies the status in the logistics system, identifies a delay, opens an internal request, prepares a response for the customer, and records the support history.
The first assistant only talks. The second organizes steps and takes action. This transition from only responding to acting in a more automated way is where the concept of an agent becomes meaningful.
In practical terms, agents usually combine a few elements:
- An AI model capable of interpreting the goal;
- Instructions that define behavior and limits;
- Tools the agent can use, such as Excel, Word, or a corporate system;
- Some mechanism of control, permission, or supervision;
- A way to track steps, results, and errors.
Recent documentation helps refine this idea. OpenAI describes agents based on components such as model, instructions, tools, guardrails, and sessions. Anthropic proposes a useful distinction between workflows and agents. In workflows, the steps are usually more predictable and defined in code. In agents, the model has more freedom to decide how to organize the process and which tools to use according to the context.
This does not represent absolute autonomy. In many cases, the agent works with supervision, limits, permissions, and well-defined goals. There is also variation in how the term is used in the market. In some contexts, any system with tools is called an agent. In others, the word is reserved for systems that operate through more steps with greater independence.
Concrete examples make this clearer. A programming tool with agentic behavior can analyze a source code repository, plan changes, edit files, run tests, and present a summary of the changes. An administrative agent can read emails, identify requests, check the calendar, and prepare responses. A sales agent can analyze leads, enrich data, and suggest next contacts.
In all these cases, the central point is the same: the system is not limited to conversation. It uses context, instructions, and tools to act toward a goal.
How Do These Concepts Connect?
When viewed separately, these terms can look like a chaotic glossary. When placed in sequence, they form a comprehensible chain.
Artificial intelligence is the broader field. Within it, machine learning explains how systems can learn patterns from data. Deep learning expands this idea using neural networks with multiple layers, capable of learning more complex representations. The AI model is the trained result of this process. It receives an input and produces an output based on learned patterns.
The Transformer architecture helps explain why modern language models can handle context and natural language so well. It introduced an efficient way to relate different parts of a sequence, especially through the attention mechanism.
Generative AI describes models used to create new content, such as text, images, audio, video, and code. Multimodality expands the types of information these systems can work with, allowing them to combine text, images, audio, and other formats.
Tokens explain how text is broken down and processed. Input and output tokens show how this processing is measured in practice. Token caching shows how part of this work can be temporarily reused in certain scenarios.
The prompt represents the way the user guides the system. It works like a briefing, bringing together the request, context, format, and constraints.
MCP appears when AI needs to connect to external tools, data, and systems in a standardized way. And the agent emerges when this set gains the ability to organize steps, use tools, and act within defined limits.
Conclusion
With companies rapidly adopting artificial intelligence systems and new developments being announced constantly, it is important to be familiar with these terms and understand how all of this works.
Instead of treating AI as a magical black box, it becomes possible to see it as a combination of methods, architectures, interfaces, and specific capabilities.
We hope this article helps you better understand how artificial intelligence systems work and what they can do. Artificial intelligence is here to stay and is already a reality across the job market.
Sources
- Artificial intelligence - Encyclopaedia Britannica. https://www.britannica.com/technology/artificial-intelligence. Accessed on 05/09/2026.
- Machine learning - Encyclopaedia Britannica. https://www.britannica.com/technology/machine-learning. Accessed on 05/09/2026.
- Deep learning - Encyclopaedia Britannica. https://www.britannica.com/technology/deep-learning. Accessed on 05/09/2026.
- Neural network - Encyclopaedia Britannica. https://www.britannica.com/technology/neural-network. Accessed on 05/09/2026.
- Attention Is All You Need - arXiv. https://arxiv.org/abs/1706.03762. Accessed on 05/09/2026.
- Large language models, explained with a minimum of math and jargon - Google Cloud. https://cloud.google.com/discover/what-are-large-language-models. Accessed on 05/09/2026.
- Generative AI - Google Cloud. https://cloud.google.com/use-cases/generative-ai. Accessed on 05/09/2026.
- What is Multimodal AI? - IBM. https://www.ibm.com/think/topics/multimodal-ai. Accessed on 05/09/2026.
- Multimodal AI - Google Cloud. https://cloud.google.com/use-cases/multimodal-ai. Accessed on 05/09/2026.
- What are tokens and how to count them? - OpenAI Help Center. https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them. Accessed on 05/09/2026.
- What is the difference between prompt tokens and completion tokens? - OpenAI Help Center. https://help.openai.com/en/articles/7127987-what-is-the-difference-between-prompt-tokens-and-completion-tokens. Accessed on 05/09/2026.
- Prompt Caching in the API - OpenAI. https://openai.com/index/api-prompt-caching/. Accessed on 05/09/2026.
- Prompt engineering overview - Anthropic Docs. https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview. Accessed on 05/09/2026.
- What is the Model Context Protocol (MCP)? - Model Context Protocol. https://modelcontextprotocol.io/introduction. Accessed on 05/09/2026.
- Building agents - OpenAI Developers. https://developers.openai.com/tracks/building-agents. Accessed on 05/09/2026.
- Reasoning models - OpenAI API Docs. https://platform.openai.com/docs/guides/reasoning. Accessed on 05/09/2026.
- Building Effective AI Agents - Anthropic. https://www.anthropic.com/engineering/building-effective-agents. Accessed on 05/09/2026.
- About GitHub Copilot cloud agent - GitHub Docs. https://docs.github.com/en/copilot/concepts/agents/cloud-agent/about-cloud-agent. Accessed on 05/09/2026.
- Claude Code overview - Claude Code Docs. https://code.claude.com/docs/en/overview. Accessed on 05/09/2026.
- Agent runtime - OpenClaw Docs. https://docs.openclaw.ai/concepts/agent. Accessed on 05/09/2026.