Introdução
Inteligência artificial é definitivamente o "hype" do momento. Novidades são anunciadas praticamente todos os dias, e as empresas têm adotado soluções diversas em ritmo acelerado, esperando obter ganhos de produtividade e retorno financeiro o mais breve possível.
Em pouco tempo, termos técnicos como aprendizado de máquina, transformer, prompt, token, agentes autônomos e MCP passaram a ser citados em reuniões, notícias, softwares e conversas de trabalho. Para quem não trabalha diretamente em uma área ligada à tecnologia, entender todos esses termos complicados é um desafio, considerando a falta de familiaridade com a área e a velocidade com que novidades são anunciadas.
Este artigo aborda os principais conceitos da área de inteligência artificial, ou simplesmente IA, considerando os termos mais usados no momento. A proposta é apresentar definições claras, exemplos práticos e comparações didáticas para que o leitor entenda como essas ideias se conectam no uso real.
O que é Inteligência Artificial?
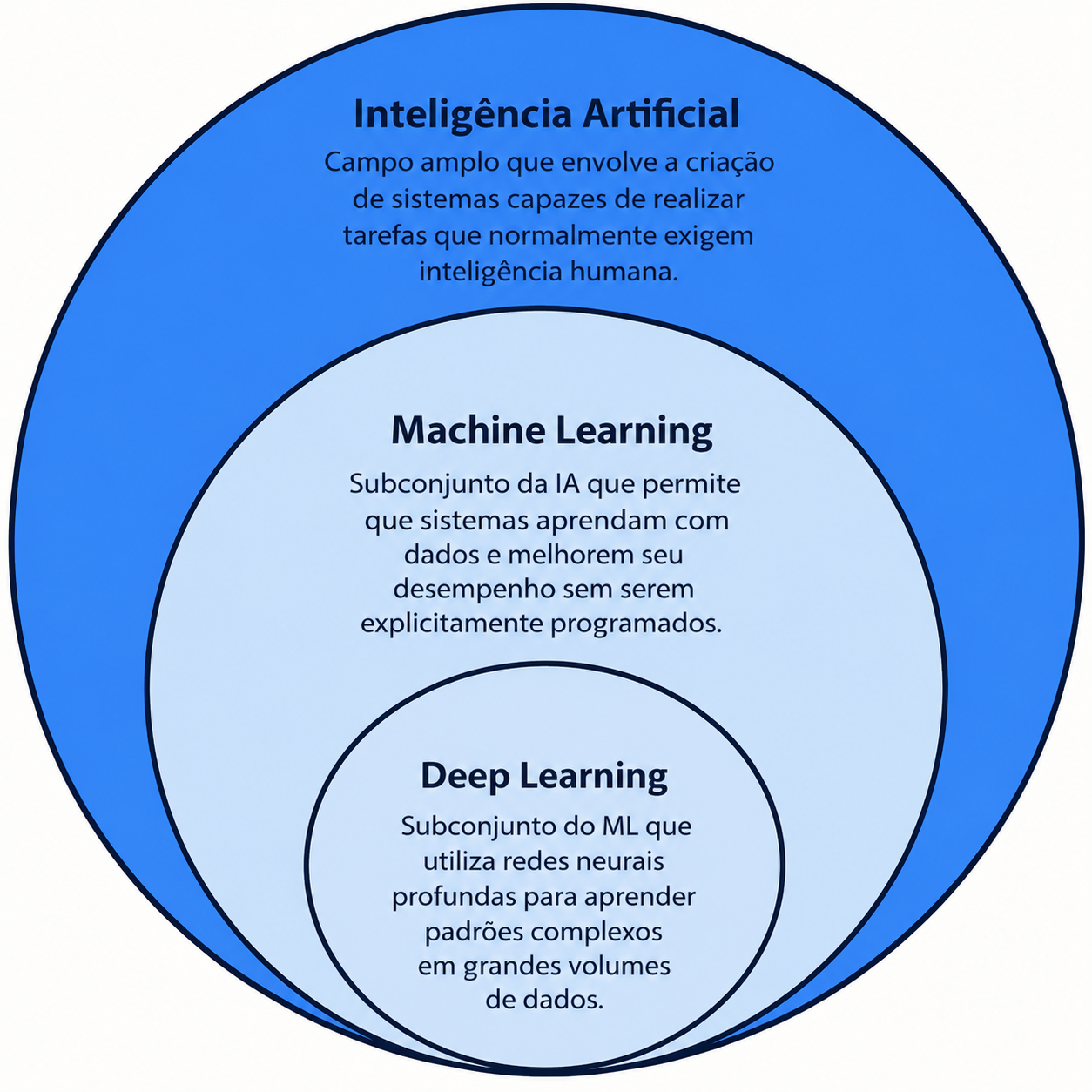
Inteligência artificial é o campo de estudos mais amplo da área. Existem diversas definições do que exatamente significa essa área, mas, em termos simples, ela reúne técnicas que permitem a sistemas computacionais executar tarefas associadas à percepção, previsão, classificação, linguagem, decisão e automação.
Dentro dessa área, existem diferentes linhas de estudo e aplicação. Vamos destacar duas delas, considerando o contexto atual de adoção de soluções de inteligência artificial no mercado.
A primeira é a área de Aprendizado de Máquina, ou, do inglês, Machine Learning.
Aprendizado de Máquina é uma forma de construir sistemas que aprendem padrões a partir de dados, em vez de depender apenas de regras escritas manualmente por programadores.
Vamos fazer uma analogia com uma pessoa aprendendo a fazer arremessos de basquete, com a ajuda de um treinador. No começo, essa pessoa erra quase tudo. A bola bate no aro, vai muito forte ou fica curta. Mas o treinador faz algo importante: após cada tentativa, ele dá feedback para melhorar as jogadas:
- "Você lançou rápido demais."
- "Dobre mais os joelhos."
- "Mire um pouco mais alto."
Com o tempo, o atleta começa a identificar padrões:
- Quando usa certa força, ele acerta a cesta com mais frequência.
- Quando posiciona o braço corretamente, o arremesso melhora.
- Quando repete movimentos errados, o resultado piora.
Depois de muitas tentativas, o cérebro dele aprende quais movimentos aumentam a chance de sucesso.
O aprendizado de máquina funciona de forma parecida. Em vez de receber uma lista rígida de instruções para cada situação possível, o sistema observa dados, ajusta seus parâmetros internos e aprende a reconhecer regularidades. É isso que permite, por exemplo, filtro de spam em e-mails, recomendação de filmes em plataformas de streaming, detecção de fraudes ou reconhecimento de voz.
A segunda área é a de Aprendizado Profundo, ou, do inglês, Deep Learning.
Essa é uma subárea de aprendizado de máquina. Ela usa redes neurais com várias camadas para aprender representações progressivamente mais complexas dos dados. Essas redes foram inspiradas de forma geral no funcionamento de neurônios, mas são estruturas matemáticas e computacionais, não cópias literais do cérebro humano.
Imagine agora um atleta profissional de futebol que precisa tomar decisões complexas durante uma partida.
Um jogador iniciante normalmente aprende orientações mais diretas:
- "Passe para quem está livre."
- "Chute quando estiver perto do gol."
- "Marque o adversário mais próximo."
Esse tipo de aprendizado lembra uma lógica mais simples de reconhecimento de padrões.
Mas um jogador profissional de elite faz muito mais do que seguir instruções diretas. Ao longo de anos, ele aprende padrões sutis do jogo:
- Reconhece formações táticas em poucos segundos.
- Prevê movimentações futuras dos adversários.
- Interpreta linguagem corporal.
- Percebe espaços vazios no campo.
- Ajusta decisões conforme pressão, tempo e contexto da partida.
O mais interessante é que ele não depende de uma única regra simples para fazer isso. O cérebro organiza várias camadas de entendimento.
Primeiro, ele percebe sinais básicos:
- A bola está vindo em certa direção.
- Um jogador adversário começou a correr.
- Um companheiro de time está se deslocando pela lateral.
Depois, combina esses sinais em interpretações maiores:
- O time adversário está tentando fechar o meio-campo.
- Há um espaço livre surgindo atrás da defesa.
- O goleiro está adiantado.
Em seguida, combina novamente essas interpretações em uma decisão mais complexa:
- Se ele tocar a bola naquele espaço agora, o companheiro poderá chegar antes do zagueiro e criar uma chance clara de gol.
O aprendizado profundo funciona de maneira parecida no sentido da construção progressiva de representações. Em um sistema de reconhecimento de imagens, por exemplo, as primeiras camadas podem identificar linhas, bordas e contrastes. Camadas intermediárias podem combinar esses sinais em formas, texturas e partes de objetos. Camadas mais profundas podem reconhecer conceitos mais completos, como rostos, animais, placas, veículos ou elementos de uma cena.
Esse exemplo ajuda a entender por que aprendizado profundo se tornou tão importante em áreas como visão computacional, reconhecimento de fala, tradução automática e modelos de linguagem. Ele é especialmente útil quando os dados são ricos, variados e difíceis de descrever apenas com regras manuais.
Existem outras áreas de estudo e técnicas de inteligência artificial usadas para diferentes propósitos. O objetivo deste artigo é ajudar o leitor a entender que nem todo sistema de IA depende da mesma técnica, e que os termos mais usados no mercado representam partes diferentes desse ecossistema.
O que é um modelo de IA?
Depois de entender aprendizado de máquina, fica mais fácil entender o que é um modelo de IA. Um modelo é, em termos práticos, o sistema treinado a partir de dados para reconhecer padrões e produzir alguma saída útil. Essa saída pode ser uma classificação, uma previsão, uma recomendação, um resumo, uma imagem, um trecho de código ou uma resposta em linguagem natural.
Uma forma simples de visualizar isso é pensar no modelo como um profissional treinado para transformar entradas em respostas prováveis. Ele recebe uma solicitação, analisa os sinais disponíveis e produz uma saída com base no que aprendeu durante o treinamento.
Voltando à analogia do esporte, imagine dois atletas da mesma modalidade. Ambos jogam futebol, mas foram treinados de formas diferentes. Um deles treinou principalmente finalizações. Outro treinou passes, leitura de jogo e posicionamento. Diante da mesma jogada, cada um pode tomar decisões diferentes porque seu treinamento, sua experiência e seus padrões internos são diferentes.
Com modelos de IA acontece algo semelhante. Dois modelos podem receber o mesmo pedido e responder de formas distintas, porque foram treinados com dados, objetivos, arquiteturas e ajustes diferentes.
No caso dos modelos de linguagem, essa ideia fica ainda mais concreta. O ChatGPT é uma interface da OpenAI que pode usar diferentes modelos. O Gemini é uma família de modelos do Google, com versões voltadas para diferentes tipos de tarefa. O Claude, da Anthropic, também é uma família de modelos usada para conversa, escrita, análise, programação e outras atividades.
Em todos esses casos, o usuário costuma interagir com um produto ou assistente. Por trás da tela, existe um ou mais modelos processando o pedido e gerando a resposta.
Isso ajuda a separar duas coisas que costumam ser misturadas. ChatGPT, Gemini e Claude podem ser vistos como produtos, interfaces e experiências de uso. Já GPT, Gemini e Claude também aparecem como nomes de famílias de modelos por trás dessas experiências, dependendo do contexto em que os termos são usados.
É nesse ponto que entram também as diferenças entre modelos mais rápidos e modelos com mais esforço de raciocínio. Em muitos produtos atuais, o usuário pode acabar interagindo com um modelo otimizado para respostas rápidas, ideal para tarefas simples, ou com um modelo configurado para usar mais etapas internas antes de responder, o que pode melhorar o desempenho em problemas mais complexos.
O melhor jeito de entender essa diferença é imaginar dois profissionais experientes. Um responde imediatamente a uma pergunta direta. O outro para, organiza hipóteses, avalia riscos, revisa mentalmente o problema e só então responde. Nos modelos de IA, essa diferença se traduz em uma troca entre velocidade, custo computacional e profundidade de processamento.
Vale um cuidado importante. Quando dizemos que um modelo aprende padrões, estamos falando de um processo estatístico e computacional. Ele não entende o mundo como uma pessoa entende, nem guarda fatos da mesma forma que uma enciclopédia. Ele calcula respostas prováveis com base no treinamento, no contexto disponível e nas instruções recebidas. É importante mencionar isso para que fique claro que os sistemas de inteligência artificial modernos não possuem consciência da mesma forma que seres humanos (pelo menos, não por enquanto).
Arquitetura Transformer
Grande parte dos modelos de linguagem mais conhecidos hoje foi construída com base na arquitetura Transformer, apresentada em 2017 no artigo Attention Is All You Need.
A palavra mais importante aqui é atenção. Em um Transformer, o sistema consegue avaliar quais partes de uma sequência de texto são mais relevantes em relação às outras. Em vez de processar uma frase apenas como uma sequência rígida de palavras uma depois da outra, o modelo consegue relacionar diferentes partes do contexto ao mesmo tempo.
Pense em alguém lendo um contrato extenso. Para entender uma cláusula no final de um documento, talvez um contrato de financiamento de imóvel ou de compra e venda de veículo. Essa pessoa talvez precise lembrar uma definição do começo do texto, uma exceção no meio e uma condição escrita em outro trecho. Um bom leitor não interpreta cada linha isoladamente. Ele cruza informações espalhadas pelo texto.
O mecanismo de atenção funciona de forma parecida. Ele ajuda o modelo a identificar quais trechos merecem mais peso naquele momento. Se uma palavra, frase ou instrução anterior for importante para interpretar o que vem depois, o modelo pode usar essa relação durante o processamento.
Essa arquitetura foi decisiva para o avanço dos Modelos Largos de Linguagem, ou LLMs, que representam os principais modelos de IA do momento (GPT 5.5, Claude Opus e Claude Sonnet, Gemini, Deepseek v4, dentre outros.). Como o texto é convertido em tokens e processado dentro de uma janela de contexto, o Transformer ajuda o modelo a lidar melhor com coerência textual, relações de longo alcance e dependências entre trechos distantes.
Ao mesmo tempo, é importante tratar o Transformer como uma arquitetura, não como sinônimo de inteligência artificial inteira. Ele é extremamente influente na geração atual de modelos de linguagem, mas a área de IA continua pesquisando outras arquiteturas, métodos e combinações de técnicas.
Para um artigo introdutório, basta entender que Transformer é uma das bases técnicas que tornaram os modelos de linguagem modernos muito mais úteis em tarefas que dependem de contexto.
O que é IA generativa?
Finalmente chegamos no conceito de Inteligência Artificial Generativa. Esta é a parte da IA voltada à criação de novos conteúdos. Esses conteúdos podem ser texto, imagem, áudio, vídeo, código e outros formatos. O ponto central é que o sistema produz uma saída nova com base em padrões aprendidos no treinamento e no contexto do pedido recebido (conceito este chamado de generalização).
Modelos generativos aprendem padrões de forma, conteúdo e estrutura a partir de grandes conjuntos de dados. Depois, usam esses padrões para compor novas saídas conforme o pedido do usuário.
Essa distinção é importante porque muita gente imagina IA generativa como uma espécie de mecanismo de busca disfarçado. Em alguns sistemas, a IA pode ser combinada com busca na internet, bases de dados, documentos internos ou ferramentas externas. Ainda assim, a lógica central do modelo generativo é produzir uma saída a partir do contexto recebido e dos padrões aprendidos.
É por isso que ferramentas generativas podem escrever um e-mail, criar uma imagem a partir de uma descrição, resumir um relatório, sugerir código ou adaptar um texto para outro público. O mesmo princípio geral vale para tipos de conteúdo diferentes, embora cada modalidade exija técnicas, dados e ajustes próprios.
Pense na forma como funciona a cozinha em um restaurante. O cozinheiro pode ter estudado centenas de receitas e técnicas. Quando recebe um pedido, ele combina ingredientes, métodos e experiência para preparar um prato novo. O resultado depende do repertório, das instruções recebidas e dos ingredientes disponíveis. Com IA generativa, o pedido do usuário funciona como parte desse direcionamento.
O que é um modelo multimodal?
Se IA generativa fala do tipo de tarefa, multimodalidade fala do tipo de dado. Um modelo multimodal é aquele capaz de lidar com mais de uma modalidade de informação, como texto, imagem, áudio, vídeo e código.
Um jeito intuitivo de imaginar isso é pensar em um médico trabalhando no diagnóstico para um paciente. Ele pode ler o histórico do paciente, observar exames de imagem, ouvir a descrição dos sintomas, comparar resultados laboratoriais e juntar tudo em uma análise mais completa. A riqueza da avaliação vem justamente da combinação de diferentes tipos de informação.
Um sistema multimodal segue uma lógica parecida no processamento computacional. Ele pode receber, por exemplo, uma imagem e uma pergunta em texto. Pode analisar um gráfico, interpretar uma captura de tela, resumir um áudio ou combinar informações visuais e textuais para produzir uma resposta.
Isso ajuda a entender uma confusão comum. IA generativa e IA multimodal são conceitos diferentes. Um sistema pode gerar apenas texto. Outro pode receber texto e imagem. Outro pode receber áudio, imagem e texto, e gerar uma resposta textual. Em alguns casos, as capacidades se sobrepõem, mas os conceitos descrevem aspectos diferentes.
Na prática, a multimodalidade é importante porque aproxima a IA do modo como lidamos com informação no cotidiano. Pessoas leem, veem, escutam, comparam e combinam sinais o tempo todo. Modelos multimodais tentam levar essa combinação para o processamento computacional.
Isso abre espaço para aplicações mais naturais. Um usuário pode enviar uma foto de um equipamento com defeito e pedir orientação. Um profissional pode enviar um gráfico e pedir uma análise. Um estudante pode mostrar uma imagem de um exercício e pedir explicação. Em vez de depender apenas de texto digitado, o sistema passa a trabalhar com mais formas de entrada.
O que são tokens?
Para entender como modelos de linguagem funcionam, é preciso entender token. Token é a unidade básica de texto que o modelo processa. Muita gente imagina que token seja igual a palavra, mas isso é apenas uma aproximação. Um token pode ser uma palavra inteira, uma parte de palavra, um espaço, um sinal de pontuação ou uma combinação curta de caracteres, dependendo do sistema de tokenização.
Uma forma prática de pensar nisso é imaginar que, antes de trabalhar com uma frase, o modelo a desmonta em pequenas peças manipuláveis. Essas peças são os tokens. Depois disso, o sistema processa relações entre elas para interpretar o contexto e gerar a próxima saída.
Imagine uma criança montando uma frase com blocos. Alguns blocos representam palavras inteiras. Outros representam pedaços de palavras. Outros representam pontuação. Para formar uma resposta, ela precisa organizar esses blocos em sequência. Modelos de linguagem trabalham com uma versão computacional dessa ideia.
Esse conceito fica mais concreto com uma conta aproximada muito usada no mercado. Em inglês, 1 token costuma corresponder a cerca de 4 caracteres, ou aproximadamente três quartos de uma palavra. Note que isso é apenas uma média, e não uma regra fixa válida para todos os modelos que trabalham com tokens. Em português, a proporção pode variar, porque as palavras têm outra estrutura e acentuação. Ainda assim, essa referência ajuda a entender a ordem de grandeza.
Um texto com 400 caracteres, por exemplo, pode ter algo em torno de 100 tokens, dependendo da língua, dos espaços, da pontuação e do modelo usado.
Isso importa por várias razões. Primeiro, porque limita o total de informações que um modelo consegue processar de uma só vez. Em vez de pensar apenas em número de páginas, sistemas de IA trabalham com janelas de contexto medidas em tokens. Segundo, porque custo e desempenho também costumam ser calculados com base em tokens. Terceiro, porque a forma como o texto é escrito afeta o volume de informação enviado ao modelo.
Quando alguém manda uma mensagem longa para um sistema de IA, o modelo não recebe aquilo como um bloco indivisível. Ele transforma o conteúdo em tokens e opera sobre essas unidades. Esse é um detalhe técnico, mas com efeito prático enorme.
O que são tokens de entrada e tokens de saída?
Além do conceito geral de token, existe uma distinção operacional importante. Tokens de entrada são os tokens enviados ao modelo. Isso inclui a pergunta do usuário, o contexto adicional, instruções do sistema e eventualmente partes anteriores da conversa. Tokens de saída são os tokens gerados pelo modelo na resposta.
Em sistemas de IA, o espaço consumido e, muitas vezes, o custo envolvido dependem dessas duas dimensões.
Se o usuário envia um prompt (vamos chegar nesse conceito em breve) muito grande, o consumo de entrada aumenta. Se pede uma resposta muito extensa, o consumo de saída também cresce. Em aplicações reais, isso afeta orçamento, velocidade e limite de contexto disponível.
Por exemplo, considere uma empresa que usa IA para analisar contratos. Se cada solicitação inclui o contrato inteiro, anexos, histórico da negociação e instruções detalhadas, o volume de tokens de entrada será alto. Se a resposta precisar trazer análise completa, riscos, sugestões de cláusulas e resumo executivo, o volume de tokens de saída também será alto. Isso impacta tanto na precisão de saída, que pode resultar em conteúdo menos preciso devido ao volume de dados, quanto custo final, que provavelmente será alto dependendo do modelo de IA utilizado.
O que é cache de token?
Outro conceito que costuma soar técnico demais é cache de token, também chamado em alguns contextos de prompt caching. A ideia geral é simples: quando parte do contexto já foi processada recentemente e continua igual, o sistema pode reaproveitar esse trabalho em vez de recalcular tudo do zero.
Imagine alguém revisando um documento longo ao longo do dia. Se os primeiros capítulos continuam idênticos e só o final mudou, essa pessoa não precisa reler tudo com a mesma atenção desde o começo. Ela pode focar no trecho alterado e reaproveitar o entendimento já construído sobre o restante.
O cache funciona como esse reaproveitamento temporário de processamento. Em aplicações com prompts longos ou repetitivos, isso pode reduzir tempo de processamento e custo, dependendo da plataforma, do modelo e das condições de uso.
Mas há um cuidado importante: cache não deve ser confundido com memória permanente. Ele não significa que a IA passou a lembrar dos dados de forma estável e duradoura. Significa apenas que certos trechos de contexto podem ser reutilizados por algum tempo em condições específicas.
Para quem usa IA em produtos, esse conceito é útil porque explica por que algumas interações longas podem ficar mais eficientes. Para quem está começando, basta entender que cache de token é uma forma de evitar retrabalho computacional quando partes do contexto se repetem, e, principalmente, evitar contas muito caras ao usar IA para processar textos longos ou outros conteúdos que exijam um alto consumo de tokens.
O que é prompt?
Prompt é a instrução, o pedido e o contexto que você fornece ao modelo. Em um sentido simples, é aquilo que orienta a resposta da IA. Pode ser uma pergunta curta, um texto com contexto, uma tarefa detalhada, um conjunto de regras ou uma combinação de tudo isso.
Basicamente, quando você abre o ChatGPT, o Gemini, o Claude, ou outro chat similar, e faz uma pergunta à IA, o que você está escrevendo é um prompt.
Um jeito direto de entender isso é pensar em um briefing. Quando alguém pede um trabalho sem contexto, sem objetivo claro e sem critérios, a chance de receber algo genérico aumenta. Quando o pedido vem com contexto, restrições, formato desejado e exemplos, a chance de receber algo útil cresce bastante.
Compare estes dois pedidos:
- "Escreva um texto sobre vendas."
- "Escreva um e-mail curto para clientes que abandonaram o carrinho em uma loja online de roupas, usando tom educado, oferecendo ajuda e evitando linguagem agressiva de venda."
O segundo pedido oferece contexto, público, objetivo, formato e restrições. Por isso, tende a produzir uma resposta mais útil.
É por isso que se fala em engenharia de prompt. O nome pode soar sofisticado, mas a lógica central é simples: formular melhor o pedido para obter melhores resultados. Isso envolve clareza, estrutura, exemplos, objetivo e limites. Esse ponto é especialmente importante porque muita gente trata prompt como um truque secreto. Na prática, o valor está em saber explicar bem a tarefa. Em ambientes profissionais, isso faz diferença em qualidade, consistência e reaproveitamento de fluxos de trabalho.
Em uma empresa, por exemplo, prompts bem escritos podem padronizar análises, relatórios, revisões de contrato, respostas de atendimento, resumos de reunião e geração de documentação. O ganho vem menos de frases especiais e mais de transformar conhecimento de processo em instruções claras.
O que é MCP?
MCP significa Model Context Protocol. Ele é um padrão aberto pensado para conectar aplicações de IA a sistemas externos, como arquivos, bancos de dados, ferramentas e fluxos de trabalho.
Pense em uma planilha do Excel ou documento do Word que você elaborou para um propósito específico no serviço. Pense também naquele sistema que sua empresa usa para gestão de recursos humanos, para abertura de chamados, dentre outros.
O MCP é basicamente um protocolo que permite conectar esses diversos sistemas e aplicações com a inteligência artificial. A principal diferença de um sistema tradicional é que no sistema tradicional, geralmente temos uma tarefa pré-definida para executar uma ação, ou uma pessoa interagindo para realizar uma tarefa. No contexto de inteligência artificial, o MCP permite a um agente de inteligência artificial tomar decisões e interagir com os sistemas e aplicações por conta própria. Basicamente, a IA decide como usar o sistema, e utiliza os comandos e instruções disponíveis da forma que achar necessário.
Esse conceito é importante porque, quanto mais a IA sai do chat simples e passa a interagir com sistemas reais, mais valiosa se torna uma forma organizada de conexão. O MCP garante que aplicações diversas adotem um padrão comum para integração com sistemas de IA, o que permite que novos modelos possam ser integrados a sistemas existentes sem grandes "dores de cabeça".
Para um leitor não técnico, a ideia central é esta: o MCP ajuda a IA a conversar com ferramentas, dados e serviços do mundo real de maneira padronizada.
Esse conceito é especialmente relevante no contexto de agentes autônomos (próximo conceito abordado), porque agentes dependem justamente da capacidade de acessar recursos fora da caixa de texto. Um agente que apenas conversa tem utilidade limitada. Um agente que consulta ferramentas, interpreta dados e executa ações pode participar de fluxos reais de trabalho.
O que é um agente autônomo?
O termo agente autônomo ganhou muita visibilidade, mas nem sempre é usado com precisão. Em linhas gerais, um agente é um sistema de IA que não apenas responde a perguntas, mas também decide etapas, usa ferramentas e executa ações em nome do usuário dentro de certos limites.
Uma forma simples de visualizar isso é comparar dois tipos de assistente.
O primeiro assistente apenas responde dúvidas. Você pergunta qual é o prazo de entrega de um produto, e ele responde com base em uma informação disponível.
O segundo assistente recebe um objetivo. Ele consulta o pedido, verifica o status no sistema de logística, identifica atraso, abre uma solicitação interna, prepara uma resposta para o cliente e registra o histórico do atendimento.
O primeiro conversa. O segundo organiza passos e age. É nessa transição de apenas responder para a ação de agir de forma mais automatizada que o conceito de agente ganha sentido.
Em termos práticos, agentes costumam combinar alguns elementos:
- Um modelo de IA capaz de interpretar o objetivo;
- Instruções que definem comportamento e limites;
- Ferramentas que o agente pode usar (sistemas diversos, como o Excel ou Word, ou mesmo sistema corporativo, por exemplo);
- Algum mecanismo de controle, permissão ou supervisão;
- Uma forma de acompanhar etapas, resultados e erros.
Documentações recentes ajudam a refinar essa ideia. A OpenAI descreve agentes a partir de componentes como modelo, instruções, ferramentas, guardrails e sessões. A Anthropic propõe uma distinção útil entre workflows e agentes. Em workflows, as etapas costumam ser mais previsíveis e definidas em código. Em agentes, o modelo tem mais liberdade para decidir como organizar o processo e quais ferramentas usar conforme o contexto.
Isso não representa autonomia absoluta. Em muitos casos, o agente trabalha com supervisão, limites, permissões e objetivos bem definidos. Também existe variação no uso do termo no mercado. Em alguns contextos, qualquer sistema com ferramentas é chamado de agente. Em outros, a palavra fica reservada para sistemas que operam por mais etapas com maior independência.
Exemplos concretos ajudam bastante. Uma ferramenta de programação com comportamento agentivo pode analisar um repositório de código-fonte, planejar alterações, editar arquivos, executar testes e apresentar um resumo das mudanças. Um agente administrativo pode ler e-mails, identificar solicitações, consultar a agenda e preparar respostas. Um agente comercial pode analisar leads, enriquecer dados e sugerir próximos contatos.
Em todos esses casos, o ponto central é o mesmo: o sistema não fica restrito a conversar. Ele usa contexto, instruções e ferramentas para agir em direção a um objetivo.
Como esses conceitos se conectam?
Quando observados separadamente, esses termos parecem um glossário caótico. Quando colocados em sequência, eles passam a formar uma cadeia compreensível.
A inteligência artificial é o campo mais amplo. Dentro dela, o aprendizado de máquina explica como sistemas podem aprender padrões a partir de dados. O aprendizado profundo amplia essa ideia usando redes neurais com várias camadas, capazes de aprender representações mais complexas. O modelo de IA é o resultado treinado desse processo. Ele recebe uma entrada e produz uma saída com base nos padrões aprendidos.
A arquitetura Transformer ajuda a entender por que modelos de linguagem modernos conseguem lidar tão bem com contexto e linguagem natural. Ela trouxe uma forma eficiente de relacionar partes diferentes de uma sequência, especialmente por meio do mecanismo de atenção.
A IA generativa descreve modelos usados para criar novos conteúdos, como texto, imagem, áudio, vídeo e código. A multimodalidade amplia os tipos de informação com que esses sistemas conseguem trabalhar, permitindo combinar texto, imagem, áudio e outros formatos.
Os tokens explicam como o texto é quebrado e processado. Tokens de entrada e saída mostram como esse processamento é medido na prática. O cache de token mostra como parte desse trabalho pode ser reaproveitada temporariamente em certos cenários.
O prompt representa a forma como o usuário orienta o sistema. Ele funciona como um briefing, reunindo pedido, contexto, formato e restrições.
O MCP aparece quando a IA precisa se conectar a ferramentas, dados e sistemas externos de forma padronizada. E o agente surge quando esse conjunto ganha capacidade de organizar etapas, usar ferramentas e agir dentro de limites definidos.
Conclusão
Com a rápida adoção de sistemas de inteligência artificial por parte das empresas, e novidades da área sendo anunciadas constantemente, é importante estar familiarizado com esses termos e entender como tudo isso funciona.
Em vez de tratar IA como uma caixa-preta mágica, passa a ser possível enxergá-la como uma combinação de métodos, arquiteturas, interfaces e capacidades específicas.
Esperamos que com esse artigo, você possa entender um pouco melhor como sistemas de inteligência artificial funcionam e o que eles podem fazer. A inteligência artificial veio para ficar e já é uma realidade no mercado de trabalho como um todo.
Fontes
- Artificial intelligence - Encyclopaedia Britannica. https://www.britannica.com/technology/artificial-intelligence. Acessado em 09/05/2026.
- Machine learning - Encyclopaedia Britannica. https://www.britannica.com/technology/machine-learning. Acessado em 09/05/2026.
- Deep learning - Encyclopaedia Britannica. https://www.britannica.com/technology/deep-learning. Acessado em 09/05/2026.
- Neural network - Encyclopaedia Britannica. https://www.britannica.com/technology/neural-network. Acessado em 09/05/2026.
- Attention Is All You Need - arXiv. https://arxiv.org/abs/1706.03762. Acessado em 09/05/2026.
- Large language models, explained with a minimum of math and jargon - Google Cloud. https://cloud.google.com/discover/what-are-large-language-models. Acessado em 09/05/2026.
- Generative AI - Google Cloud. https://cloud.google.com/use-cases/generative-ai. Acessado em 09/05/2026.
- What is Multimodal AI? - IBM. https://www.ibm.com/think/topics/multimodal-ai. Acessado em 09/05/2026.
- Multimodal AI - Google Cloud. https://cloud.google.com/use-cases/multimodal-ai. Acessado em 09/05/2026.
- What are tokens and how to count them? - OpenAI Help Center. https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them. Acessado em 09/05/2026.
- What is the difference between prompt tokens and completion tokens? - OpenAI Help Center. https://help.openai.com/en/articles/7127987-what-is-the-difference-between-prompt-tokens-and-completion-tokens. Acessado em 09/05/2026.
- Prompt Caching in the API - OpenAI. https://openai.com/index/api-prompt-caching/. Acessado em 09/05/2026.
- Prompt engineering overview - Anthropic Docs. https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview. Acessado em 09/05/2026.
- What is the Model Context Protocol (MCP)? - Model Context Protocol. https://modelcontextprotocol.io/introduction. Acessado em 09/05/2026.
- Building agents - OpenAI Developers. https://developers.openai.com/tracks/building-agents. Acessado em 09/05/2026.
- Reasoning models - OpenAI API Docs. https://platform.openai.com/docs/guides/reasoning. Acessado em 09/05/2026.
- Building Effective AI Agents - Anthropic. https://www.anthropic.com/engineering/building-effective-agents. Acessado em 09/05/2026.
- About GitHub Copilot cloud agent - GitHub Docs. https://docs.github.com/en/copilot/concepts/agents/cloud-agent/about-cloud-agent. Acessado em 09/05/2026.
- Claude Code overview - Claude Code Docs. https://code.claude.com/docs/en/overview. Acessado em 09/05/2026.
- Agent runtime - OpenClaw Docs. https://docs.openclaw.ai/concepts/agent. Acessado em 09/05/2026.